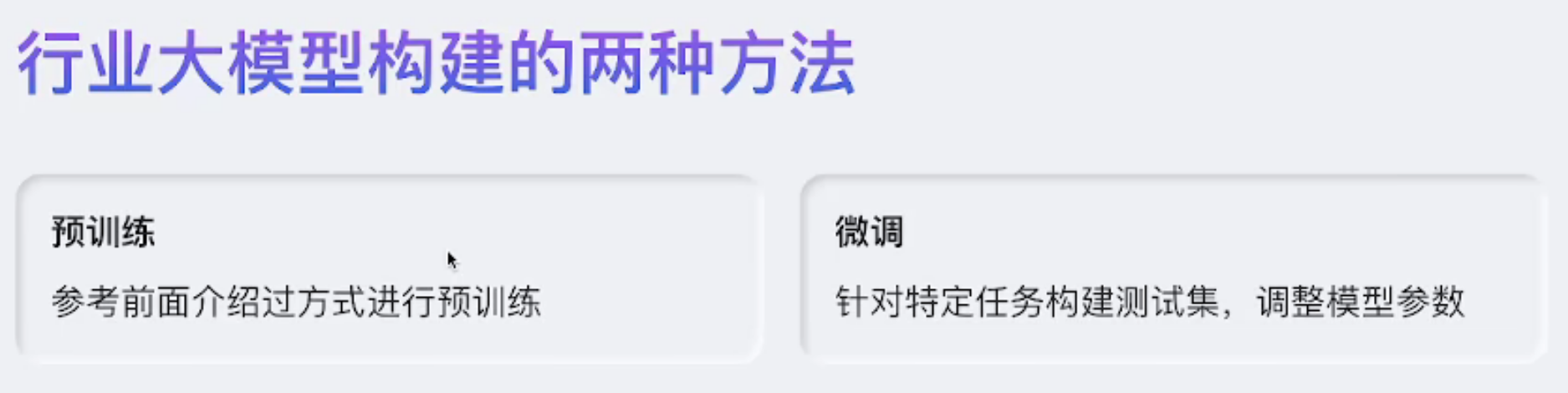
概念
智能体
基于对话的AI项目,它通过对话方式接收用户的输入,由大模型自动调用插件或工作流等方式执行用户指定的业务流程,并生成最终的回复。智能客服、虚拟伴侣、个人助理、英语外教都是智能体的典型应用场景
插件
插件是一个工具集,一个插件内可以包含一个或多个工具(API)
工作流(Workfiow)
用于处理功能类的请求,可通过顺序执行一系列节点实现某个功能。适合数据的自动化处理场景,例如生成行业调研报告、生成一张海报、制作绘本等
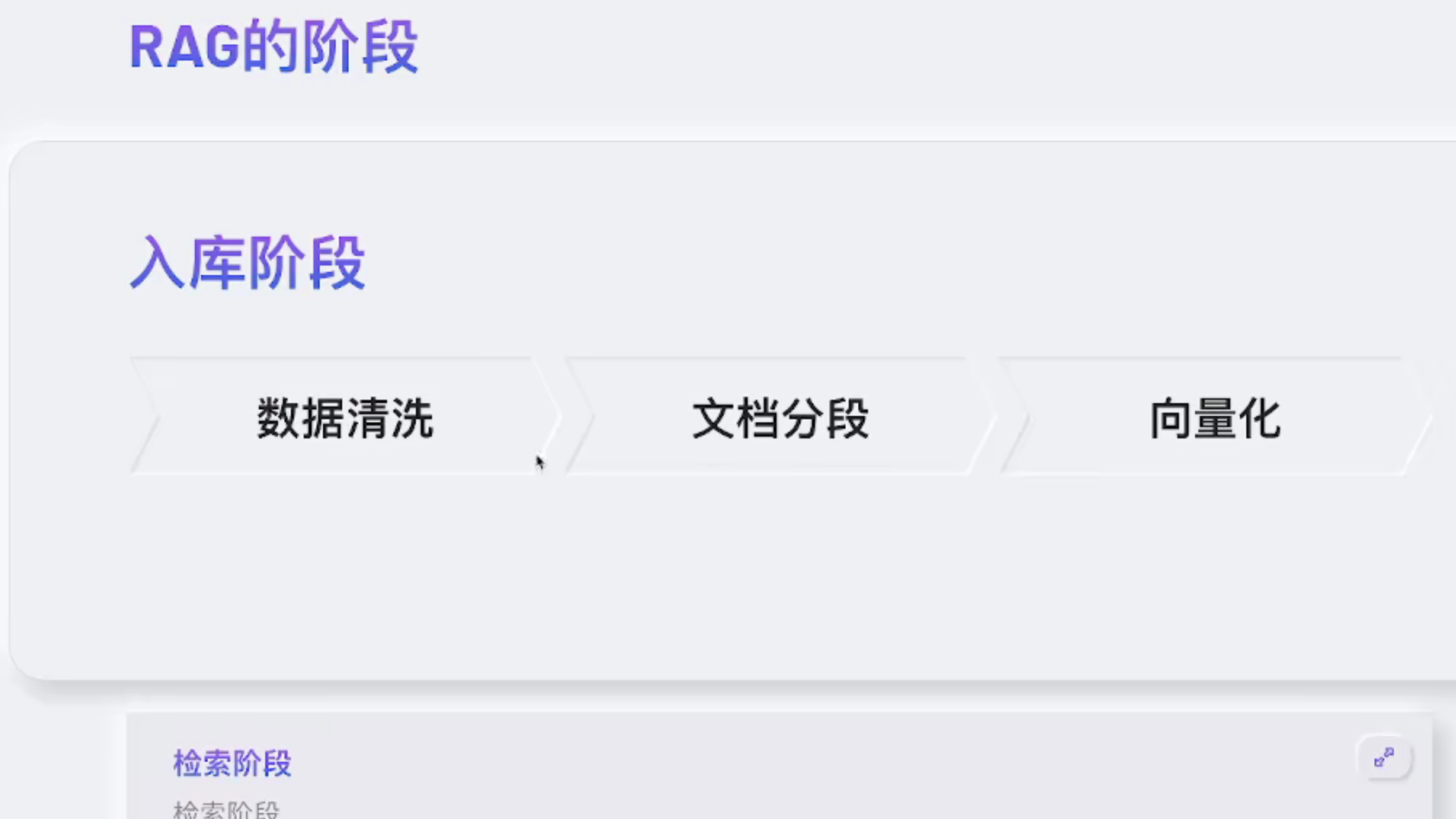
知识库:
知识库功能包含两个能力,一是存储和管理外部数据的能力,二是增强检索的能力
训练->部署大模型-> 推理
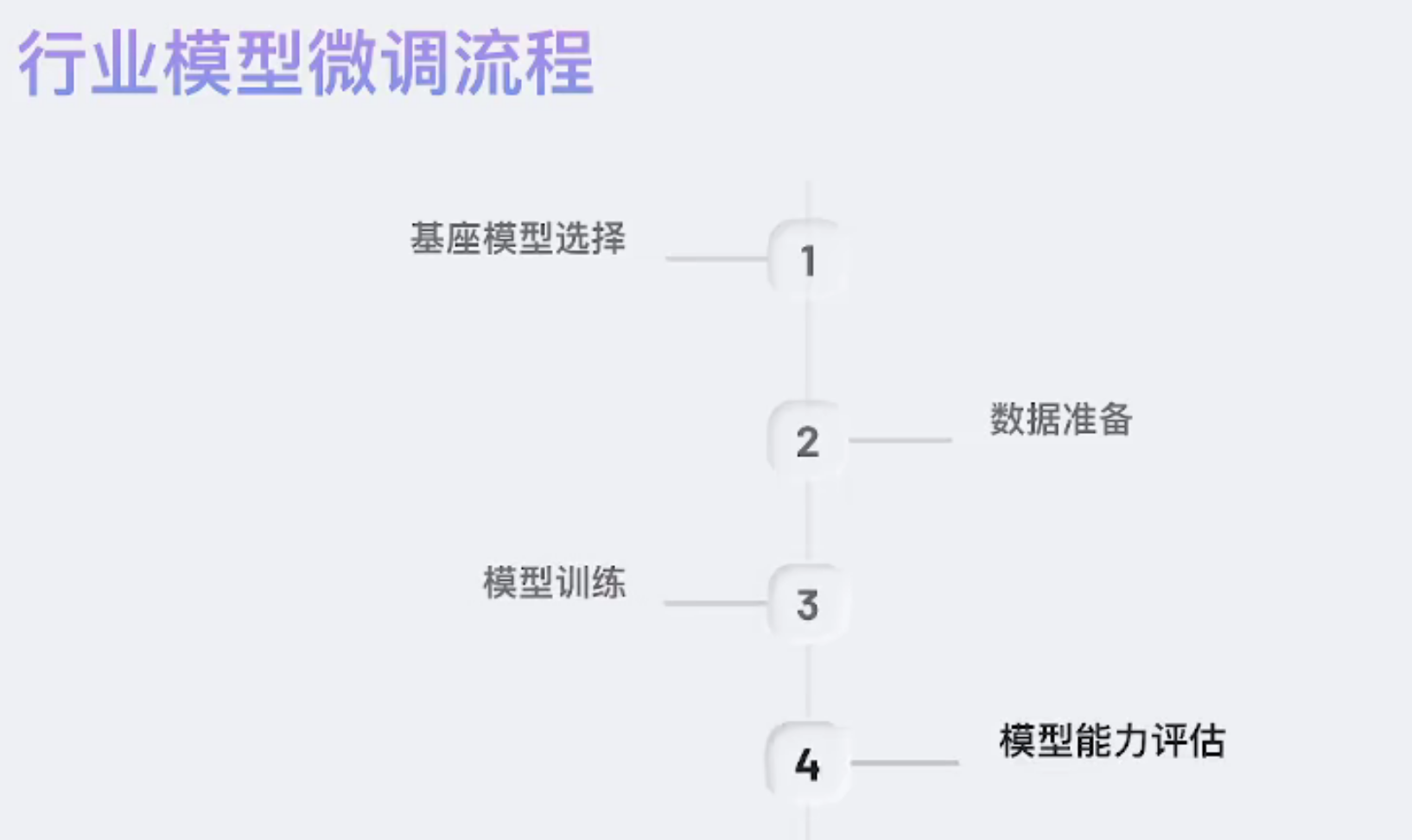
微调

过拟合: 模型在训练数据上表现得非常好,但在新数据(测试集、实际应用场景)上表现很差。
缺点:

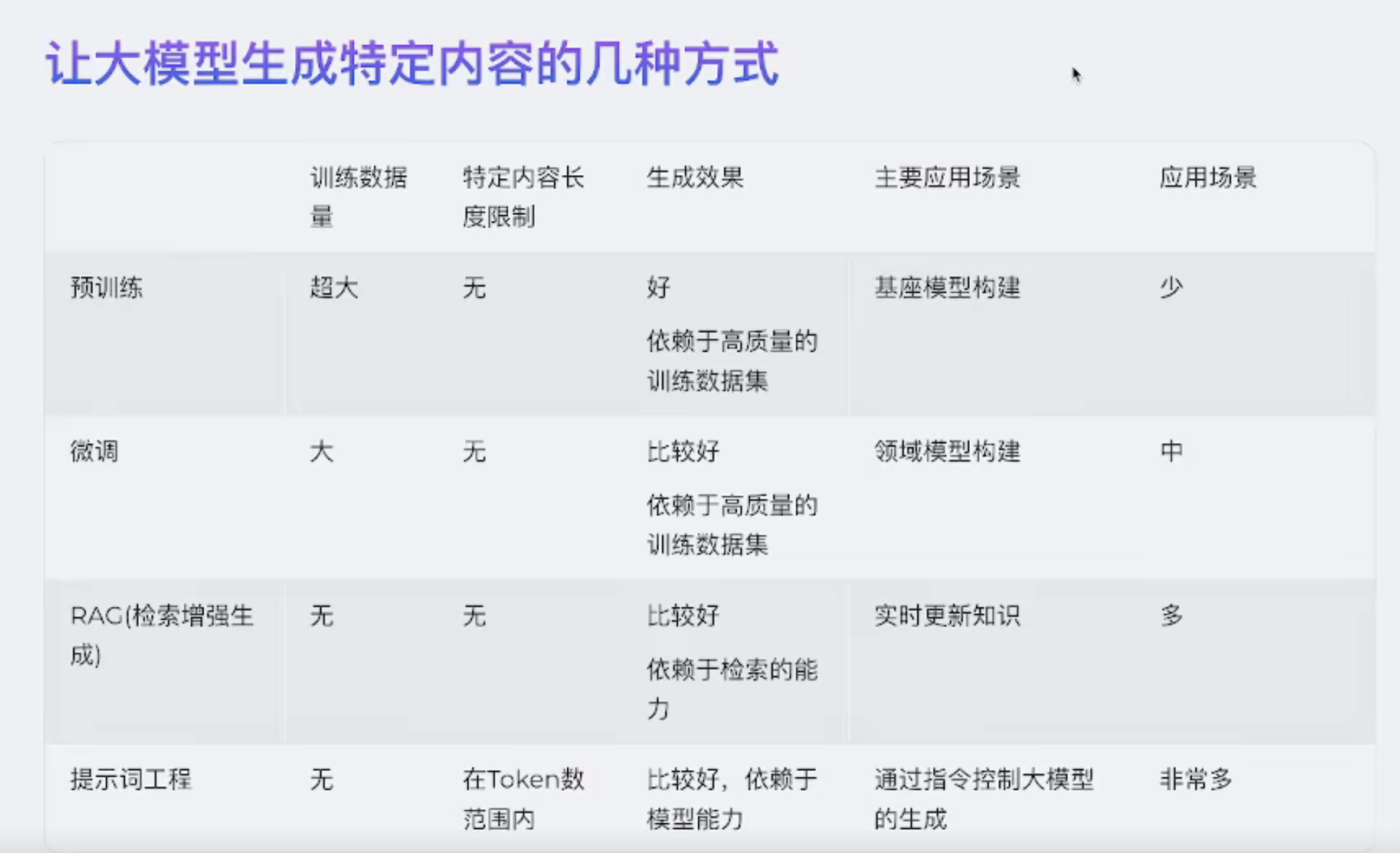
RAG
与微调的区别:微调会改变模型文件,rag不会

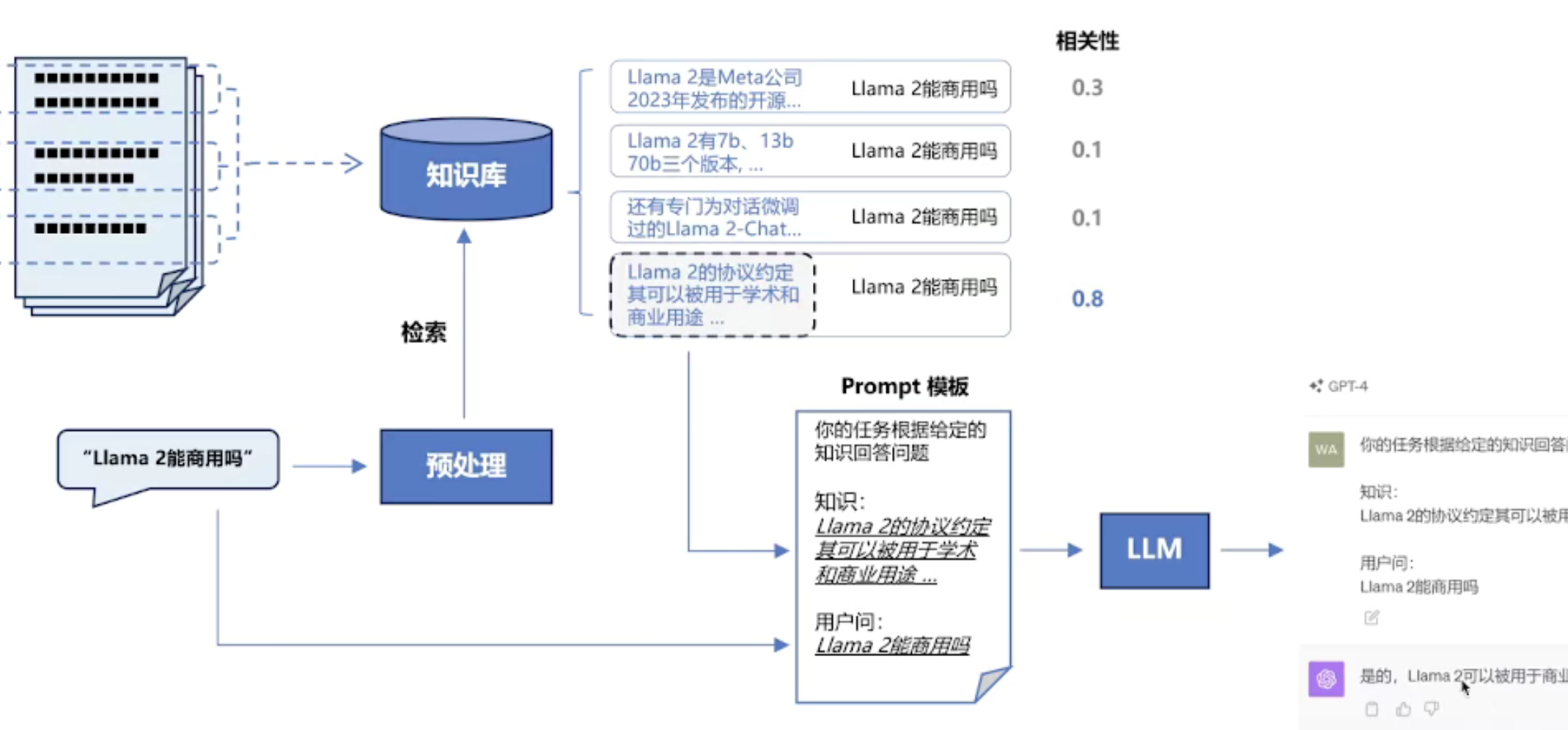


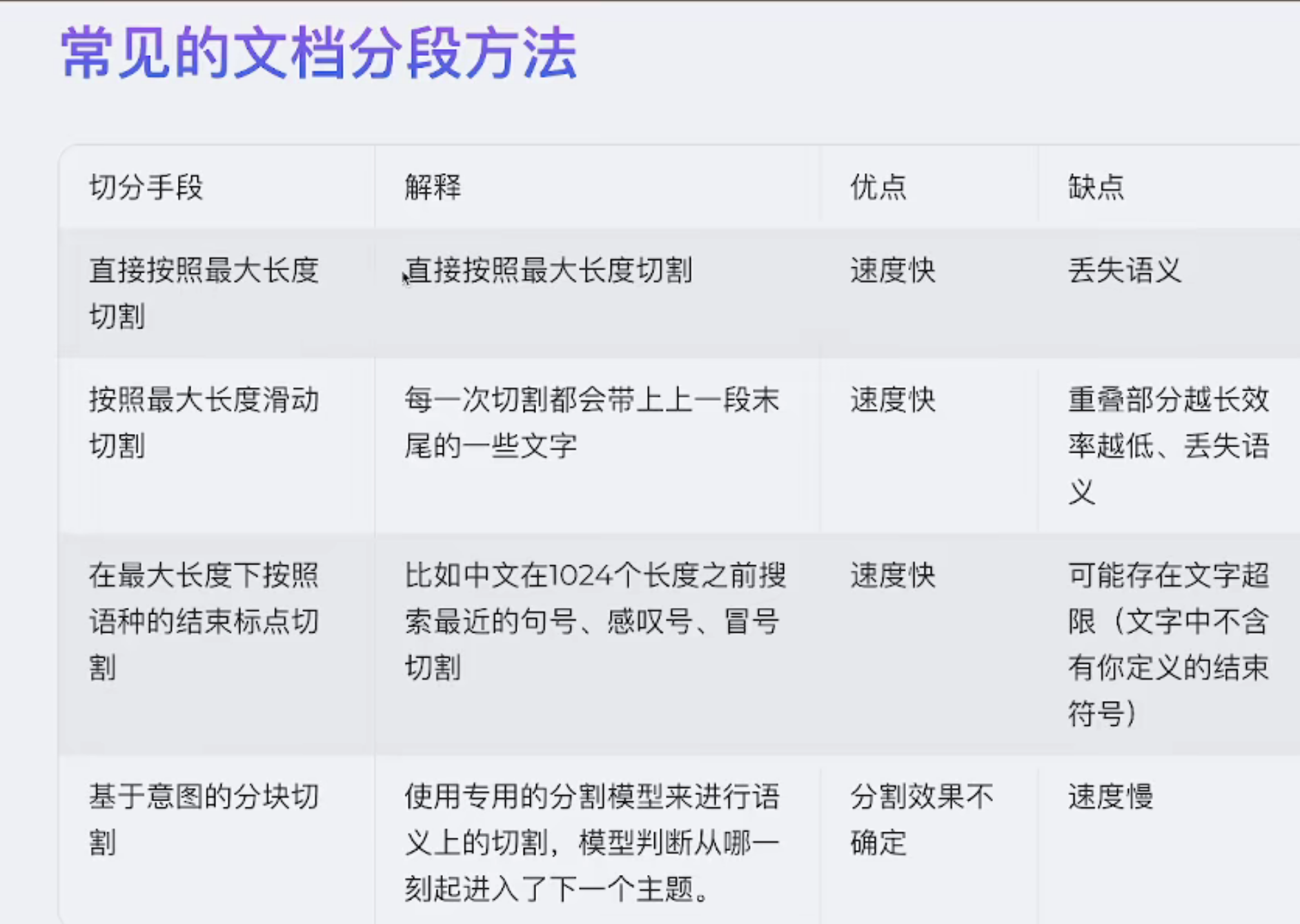

RAG 的检索流程
- 向量化
- 把用户的问题(query)通过 向量模型(比如 Sentence-BERT,或者更强的 embedding 模型)转成一个向量。
- 把知识库里的文档也提前分片、向量化,存到一个 向量数据库(如 FAISS、Milvus、Pinecone)中。
- 相似度检索
- 在向量数据库里,用余弦相似度、点积、欧式距离等方法,找到和 query 最接近的向量(对应的文档片段)。
- 这个过程就是“检索”。
- 召回结果
- 把最相关的文档片段(比如 top-k 个)作为“召回结果”返回。
- 有时会再做 重排序(Re-ranking),保证真正相关的内容排前面。
- 增强生成
- 把召回到的内容塞到 prompt 里,和用户问题一起喂给大模型,让模型基于检索结果来生成回答。
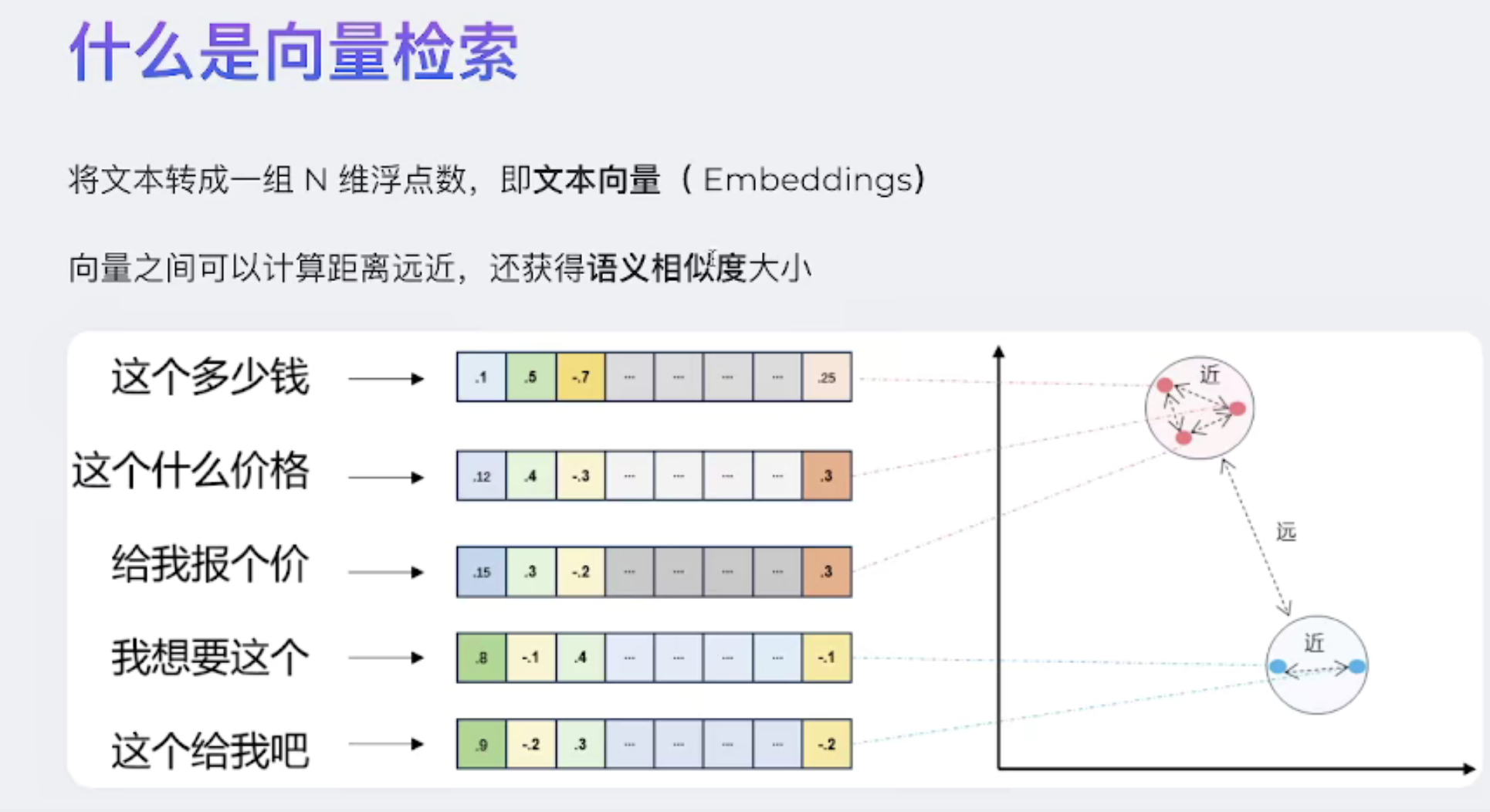
嵌入模型
指 Embedding Model,主要用来把文本、图片、音频等数据转换成向量表示(一串高维数字),让计算机能理解并处理这些非结构化数据。
简单理解:
- 传统计算机只能处理数字。
- 自然语言(文字)、图像、语音等都需要转化成“向量”,才能进行计算。
- 嵌入模型的作用就是把复杂的信息转成向量,并且让相似的内容在向量空间中“靠近”。

